Sommaire

Je suis actuellement Responsable SEO et web Analytics du groupe EBRA. J'ai ouvert ce blog pour partager des astuces, des tuto, ou des informations plus orientées techniques et opérationnelles.
- Looker Studio : gérer les dates et la granularité dans les graphs - 14 mars 2023
- Optimiser les pages avec les bons mots clés (DataStudio + Google Search Console) - 29 novembre 2020
- Seocamp 2020, les slides ? - 9 octobre 2020
Après une longue introduction aux fonctions et modules utiles sur Google Sheet pour le SEO, voici des fonctions un peu plus avancées qui demandent de connaître les expressions régulières et le xpath. C’est un des points fort de Google Sheet face à Excel, les fonctions inédites et bien pratiques.
Rappel de la série :
- 1ere partie : les modules complémentaires et fonctions basiques (similaires à excel)
- 2e partie : les fonctions import et regex, spécifiques à Google Sheets, le point fort de Google Sheets
- 3e partie : les fonctions personnalisées avec Apps scripts
Les regex : les fonctions bonus sur Google Sheet
Vous ne savez pas ce qu’est une regex ? Il faut commencer par lire ce guide sur les regex.

Vous voulez tester vos regex ? Parfait, il existe 3 fonctions qui utilisent les expressions régulières :
- REGEXMATCH(texte; expression_régulière) : pour voir si votre cellule correspon à l’expression régulière. C’est donc une formule bouléenne qui renvoie VRAI ou FAUX.
- REGEXEXTRACT(texte; expression_régulière) : pour extraire une chaine de caractère
- REGEXREPLACE(texte; expression_régulière; remplacement) : une fonction « substitue » plus poussée : pour remplacer une valeur par une autre, mais la correspondance n’est pas qu’exacte.
Vos regex ne fonctionnent pas ? Il y avait également un article sur les erreurs fréquentes dans les regex.
Exemples d’utilisation de regexreplace
Dans une optique SEO, la fonction regexreplace peut être pratique pour tester une réécriture d’URL, voir si tous les cas sont bien pris en compte.
Ou bien, vous avez une liste de nom/prénom, vous souhaitez transformer en prénom nom, c’est facile avec regexreplace. Si les noms sont en majuscule et les prénoms en minuscule (sauf la première lettre), cette fonction fera l’affaire :
regexreplace(A2; »([A-Z- ]+[A-Z- ]*) ([A-Z][a-z- ]+[A-Z]?[a-z-]*) »; »$2 $1″)
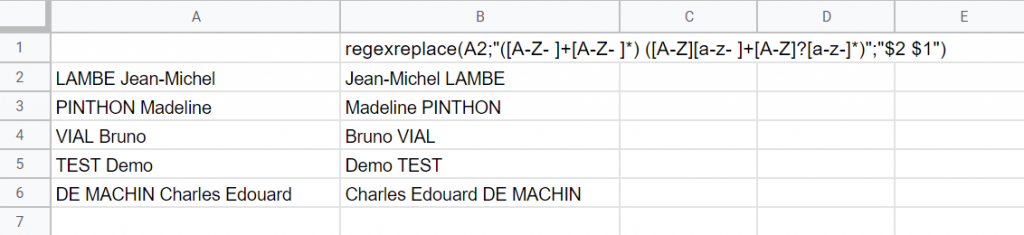
Avec ceci, vous avez je pense toutes les cartes en main pour exploiter pleinement ces fonctions.
Un cas concret pour regexextract ?
Si je m’inspire de l’exemple de la liste de nom prénoms, si vous souhaitez extraire uniquement les prénoms, cela se fait rapidement.
Regexextract permet d’extraire la partie entre parenthèse de l’expression réguliere. Dans l’exemple ci-dessus, il faut donc identifier la partie de la regex qui permet d’identifier le nom, et celle qui permet d’identifier le prénom… il suffira de conserver uniquement la partie prénom entre parenthèse ;
=REGEXEXTRACT(A2; »[A-Z- ]+[A-Z- ]* ([A-Z][a-z- ]+[A-Z]?[a-z-]*)« )
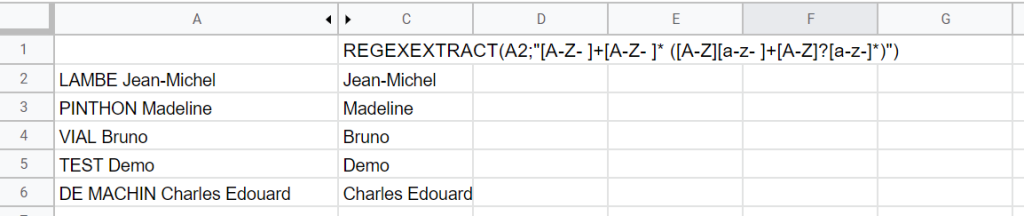
Si vous avez une liste d’URL produit qui contient le nom du produit_ID-produit, vous souhaitez extraire l’ID (ou le nom) : les regex seront vos amis.
Scrapper avec les fonctions import (importhtml, importxml, importfeed,…)
Il existe plusieurs fonctions qui permettent d’importer des données dans google sheet.
La plus connue est importxml et j’avais fait ma 1ere conférence sur le sujet (Google Black Day #1). Le recap avait été fait ici :
http://www.canyouseome.com/google-black-day-scraper-excel-spreadsheet/
Pour bien utiliser la fonction importxml, il faut avoir quelques notions de xpath. Et voici une antisèche qui dépannera dans de nombreux cas :

Pour comprendre une requête xpath, il faut remonter le fil. Chaque Slash est une étape, un noeud du document. Le document en question, c’est le document HTML (voire le DOM). Il contient donc des balises et des attributs.
Comme indiqué dans l’image, le @ permet de sélectionner l’attribut d’une balise.
Les crochets permettent d’indiquer des conditions : on les traduira par « qui ont » (ou qui n’ont pas s’il y a un NOT).
Généralement, on commence par // pour obtenir toutes les balises. Si on commençait par un simple slash, on partirait de la racine du document.
Importxml : scrapper les éléments d’une page
Décortiquons une requête xpath
Prenons l’exemple //a[not(contains(@rel, ‘nofollow’))]/@href
Pour lire la requête, on commence par « Tous les » puis ont prend le dernier élément et on remonte le fil : chaque / pourra être traduit par « qui sont dans ».
On voit qu’il y a que 2 noeuds:
a[not(contains(@rel, ‘nofollow’))] et @href
Donc // ==> « tous les », puis ont part de la fin ==> @href. Tous les @href, soit tous les attributs @href.
On remonte : tous les (//) attributs (@) href qui sont dans (/) des balises a.
Observons de plus près les conditions liées aux balises a :
contains(@rel, ‘nofollow’) : les attributs rel (@rel) contiennent (contains) ‘nofollow’. Mais on ajoute un NOT devant… donc ce sont des balises A qui n’ont pas d’attribut REL qui contient NOFOLLOW.
Si je mets bout à bout tous les éléments : je veux tous les attributs href qui sont dans des balises a qui n’ont pas d’attribut rel qui contient nofollow.
En plus simple : je ne veux pas des liens nofollow. Donc je veux tous les liens follow.
Construire une requête xpath : décomposer et assembler
Pour construire la requête, je décompose et reconstitue les éléments.
Comment identifier des liens follow ? Les liens, ce sont des balsies a et elles n’ont pas d’attributs nofollow.
Je retranscris tout cela en xpath : pas d’attributs nofollow…il y a plusieurs choses à décomposer. Déjà, le nofollow est dans un attribut rel… donc j’aurai du @rel et du nofollow. Contenir, c’est une syntaxe particulière : contains(élément dans lequel on cherche,’valeur cherchée’) : contains(@rel, ‘nofollow’)
Ici, cela ne contient pas, donc je dois ajouter le not : not(contains(@rel, ‘nofollow’)). C’est une condition de ma balise a[not(contains(@rel, ‘nofollow’))]. Le lien est dans l’attribut @href (sinon, je n’ai que les ancres).
Je rassemble tout : //a[not(contains(@rel, ‘nofollow’))]/@href
Syntaxe de la formule importxml
Cette leçon expresse de xpath permet d’utiliser la fonction importxml : =importxml(URL, Xpath)
L’URL, c’est le document dans lequel on va appliquer la requête xpath. Tout cela pour ça.
Ah si petite astuce si vous souhaitez votre URL via des fonctions (concatener par exemple), la fonction URLENCODAGE (ENCODEURL) peut être pratique. Elle permet d’encoder directement les caractères spéciaux.
Les autres fonctions import
importhtml : pour extraire les tableaux et les listes
C’est une fonction simplifiée d’importxml : elle permet d’importer les listes ou les tableaux d’une page : IMPORTHTML(url; requête; index)
IMPORTRANGE : importer des données d’un autre google sheet
La syntaxe : importrange(clé_feuille; chaîne_plage)
Et l’exemple : IMPORTRANGE(« https://docs.google.com/spreadsheets/d/abcd123abcd123 »; « Feuille1!A1:C10 »). L’exemple vient de l‘aide de Google et me semble assez parlant.
Pour les fonctions suivantes, je vous invite encore à lire l’aide de Google.
Importer un CSV avec ImportDATA et un flux RSS avec ImportFeed
Il suffit d’indiquer l’url du csv : importdata(« url ») ou celui du flux pour importfeed.
L’aide est ici pour importdata :
https://support.google.com/docs/answer/3093335?hl=fr&ref_topic=9199554
Et là pour importfeed :
https://support.google.com/docs/answer/3093337?hl=fr&ref_topic=9199554
Importer un Json ?
La fonction n’est malheureusement pas native sur googlesheet. Ca aurait été tellement plus simple pour aller piocher dans des API….mais non. Soit il faut un module complémentaire (comme nous l’avions vu dans le précédent article), soit il faut créer une fonction personnalisée.
Et finalement, cela fera l’objet d’un 3e article.
Mais si vous voulez en savoir un peu plus, il y avait les slides du WebCampDay (vous savez, le temps où les rassemblements publics étaient autorisés) :

Merci Madeline, grâce à cet article je comprends enfin un peu mieux comment fonctionne le xpath. Je suis impatient de lire la suite, j’ai quelques idées en tête pour le suivi de mes BL avec Google Sheets. 🙂
Ce n’est pas une explication officielle ou formelle mais c’est comme cela que je l’ai retenu (mais il y a un article en brouillon sur les bases du xpath, peut être que l’auteur le publiera un jour).
Contente que ça puisse servir à d’autres 🙂
Salut salut Madeline,
Merci pour toutes ces précieuses infos ! (J’ai tout d’abord ton article /guide-regex/).
Je commence à bien comprendre le principe des RegEx et du xPath nécessaire pour des requêtes XML de base (type h1, h2, liens, etc.)
Néanmoins dès que l’info que je cherche est bien plus précise sur une page, mes requêtes XML (sur Googlespreadsheet) ne donnent rien alors qu’il me semble utiliser la nomenclature réglementaire et également avoir le xPath correct.
Exemple : En imaginant par exemple que je souhaite récupérer le numéro de téléphone « 01 40 51 78 52 » qui se trouve sous l’adresse du restaurant « 24 rue chanoinesse » à cette URL : http://bing.com/search?q=restaurant+paris+au+vieux+paris
Si je fais clic-droit > copy > xPath (ou full xPath) dans le code HTML de la page, je récupère ça :
//*[@id= »b_tabsContainer »]/div[3]/div[1]/div/div/div/div[1]/div[1]/div/div/div/div[4]/div[1]/div/div[2]
Et ensuite si je lance ma requête sur Spreadsheet :
=ImportXML(« URL ci-dessus »); »xPath ci-dessus »)
J’ai un message #ERROR : Erreur d’analyse de formule…
As-tu une idée d’où ma requête pêche ?
Merci d’avance pour ta réponse si jamais 😉
Il peut y avoir plusieurs choses.
Deja les guillemets :dans ta requete xpath, remplace les » par des ‘, pour le nom de l’id… sinon il y a un conflit avec l’argument de la fonction.
Après plus une requête est longue, plus elle cible un élément précis….et plu ça peut être compliqué à reproduire.
Il est plus simple de regarder le code et de créer la requête manuellement.
Là, c’est « toutes les 2e div, dans une div, dans la 1ere div, de la 4e div, de la div, de la div, de la div, de la 1er div, de la 1ere div, de la div, de la div, de la div, de la 1ere div, de la 3e div, de l’élément ayant pour ID b_tabsContainer ».
Et ce n’est pas l’élément le plus simple à récupérer pour débuter 😉
Merci des conseils !
Effectivement, pour commencer, les guillemets à la française c’est moyen :-‘)
À part ça, si je comprends bien : l’option clic-droit > Inspecter > puis à nouveau clic-droit > copy xpath n’est pas viable ?
Du coup je vais me mettre à créer mes requêtes manuellement s’il n’y a pas d’autres moyen … Merci encore 😉
Salut Madeline,
Bon, avant de faire le mec pointilleux, on va commencer par le positif : bravo pour l’article qui pose les bases et explique les principaux points de XPath avec un exemple concret !!
Le monde du XPath manque clairement de How-To (notamment en FR) et tu fais partie des personnes qui contribuent à ce que cela change, donc GG 😉
Pour faire le mec pointilleux maintenant (en espérant que WordPress ne me pète pas la syntaxe de la regex), tu aurais pu utiliser dans ton premier exemple le pattern suivant :
([A-Z’\- ]+)\s([\w\- ]+)
Keep the good vibe et peut-être à bientôt sur un event 😉
Pour la regex, c’est un piège pour voir si les gens suivent :p 😉
Excellent article!
Je crois pouvoir ajouter ma petite pierre à l’édifice 🙂
J’ai créé ImportFromWeb, l’équivalent de IMPORTXML mais sous stéroïdes (Scrape Javascript et passe les portes de 95% des sites web) ainsi que ImportJSON pour importer des APIs.
https://nodatanobusiness.com/importfromweb/
https://nodatanobusiness.com/importjson/
N’hésite pas à tester et en parler dans l’article…
merci, je regarderai (et compléterai plutot celui qui parle des modules 😉 ).
Bonjour Madeline, merci pour cet article! Effectivement faire du scraping avec Google Sheet permet de gagner pas mal de temps quand on fait du SEO ! Personnellement, je l’utilise plutôt pour faire du SEO on page comme dans ce document: https://docs.google.com/spreadsheets/d/1Ik2aKCNtDRh7tP_rdGjlkp3y1X8Hjs1dD7sqNMPqYt8/edit#gid=840686088