Sommaire

Je suis actuellement Responsable SEO et web Analytics du groupe EBRA. J'ai ouvert ce blog pour partager des astuces, des tuto, ou des informations plus orientées techniques et opérationnelles.
- Looker Studio : gérer les dates et la granularité dans les graphs - 14 mars 2023
- Optimiser les pages avec les bons mots clés (DataStudio + Google Search Console) - 29 novembre 2020
- Seocamp 2020, les slides ? - 9 octobre 2020
Pour bien commencer l’année, iProspect a proposé un webinaire sur le temps de chargement des sites que j’ai eu l’honneur de présenter. La vitesse des sites, j’en avais déjà parlé à Nantes l’an dernier au Web2Day (Comment mesurer la vitesse des sites), en présentant surtout la multitude d’indicateurs présents dans ce domaine….si vous préférez la lecture, je ne peux que vous recommander l’article (payant) paru sur Reacteur.com : pourquoi et comment travailler la webperf ?
La vitesse des sites, ce que le rapport d’expérience utilisateur de Chrome (CrUX) nous dévoile
Vous pourrez retrouver l’intégralité des données sur le blog d’iProspect. Sur celui-ci, nous allons surtout regarder la partie technique et comment obtenir ces données dans BigQuery.
Qu’est-ce que le Chrome UX Report ?
Google met à disposition une partie des données du rapport d’expérience utilisateur de Chrome (ou Chrome UX Report, ou CrUX). Les informations sont agrégées par site, ou sous-domaine (origin). Les utilisateurs de Chrome, le navigateur le plus répandu, peuvent choisir de partager anonymement leurs données. Pour les éditeurs de site, cela permet ensuite d’avoir des informations sur la vitesse du site. Les données sont également disponibles dans Page Speed Insights (PSI).
Avec BigQuery, les données ne sont pas actualisées aussi rapidement que sur PSI. L’ajout des données arrive une fois par mois, souvent en milieu/fin de mois (le 10 janvier 2019, les données de décembre 2018 ne sont pas encore publiées). Dans PSI, on peut avoir les informations pour une page donnée. Dans les données publiques du CrUX, on ne peut avoir que l’agrégation par origin (sous-domaine).
Si vous souhaitez vraiment en savoir plus, celui qui en parle le mieux (il est payé pour) s’appelle Rick Viscomi :
(si vous vous intéressez à la webperf, il fallait être à We Love Speed à Bordeaux)
Comment obtenir les données du CrUX dans BigQuery ?
A l’origine, l’article d’Aymen Loukil « E-commerce : classement Top sites en performance » m’a bien servi, les requêtes utilisées pour les faire aussi (https://github.com/AymenLoukil/Chrome-user-experience-report-queries).
Un autre article qui m’avait bien aidé était rédigé par Rick Viscomi, qui a en plus développé le connecteur du CrUX pour Google Data Studio : A step by step guide to monitoring the competition with the Chrome UX report. Cet article est vraiment intéressant pour voir les différentes façons de présenter les données et de les obtenir. Rick Viscomi contribue énormément à promouvoir le CrUX, il participe beaucoup dans les discussions sur httparchive pour proposer des requêtes et répondre aux questions (sans oublier les conférences sur le sujet et les vidéos Google).
Et maintenant, si vous êtes curieux et débrouillard, vous avez tout le nécessaire pour fouiller dans les données et faire autant de graphiques que vous souhaitez.
Si vous êtes flemmard, voici les requêtes SQL que j’ai utilisées.
Comparer plusieurs sites entre eux
Après avoir lu les 2 articles précédents, je voulais pouvoir comparer plusieurs sites en utilisant la même présentation disponible sur data Studio. Mais sur data studio, on compare des dates et non des sites entre eux.
Je voulais obtenir cela :
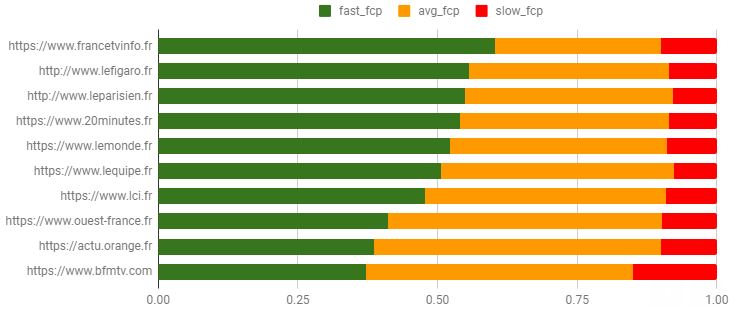
Pour cela, on interroge uniquement la base de données du rapport UX de chrome, à une date donnée. Il est très facile d’ajouter le type d’appareil utilisé, ou bien le type de connexion, ou ces 2 éléments. Si le site est inclus dans le rapport, on aura les données demandées.
#standardSQL SELECT origin, ROUND(SUM(IF(bin.start < 1000, bin.density, 0)) / SUM(bin.density), 4) AS fast_fcp, ROUND(SUM(IF(bin.start >= 1000 AND bin.start < 2500, bin.density, 0)) / SUM(bin.density), 4) AS avg_fcp, ROUND(SUM(IF(bin.start >= 2500, bin.density, 0)) / SUM(bin.density), 4) AS slow_fcp FROM `chrome-ux-report.country_fr.201811`, UNNEST(first_contentful_paint.histogram.bin) AS bin WHERE origin IN ( 'https://www.francetvinfo.fr', 'https://www.20minutes.fr', 'http://www.lefigaro.fr', 'https://www.lemonde.fr', 'https://actu.orange.fr', 'https://www.bfmtv.com', 'http://www.leparisien.fr', 'https://www.lci.fr', 'https://www.ouest-france.fr', 'https://www.lequipe.fr' ) GROUP BY origin
Obtenir le FCP median (ou le 90e centile) d’un site
Ce chiffre qui apparaît directement sur Page Speed Insights n’est pas aussi facile que cela à calculer. Dans le CrUX, on ne trouve pas directement les indicateurs mais on peut voir une répartition. Pour calculer une médiane, il faut donc passer par une étape intermédiaire.
Et la voici :
#standardSQL
SELECT
MIN(start) AS median_fcp
FROM (
SELECT
bin.start,
SUM(bin.density) OVER (ORDER BY bin.start) AS cdf
FROM
`chrome-ux-report.country_fr.201811`,
UNNEST(first_contentful_paint.histogram.bin) AS bin
WHERE
origin = 'https://www.canyouseome.com')
WHERE
cdf >= 0.9
Si vous voulez la médiane, il suffit de mettre cdf >=0.5.
(Merci à Rick Viscomi pour cette requête).
Comment évolue le FCP médian par mois ?
Après avoir vu comment comparer plusieurs sites, vous pourriez vous dire : maintenant, je souhaite voir l’évolution du FCP médian (c’est quand même plus facile à lire qu’une évolution de la densité du FCP rapide).
#standardSQL
SELECT
date,
MIN(start) AS median_fcp
FROM (
SELECT
_TABLE_SUFFIX as date,
bin.start,
SUM(bin.density) OVER (PARTITION BY _TABLE_SUFFIX ORDER BY bin.start) AS cdf,
SUM(bin.density) OVER (PARTITION BY _TABLE_SUFFIX) AS total
FROM
`chrome-ux-report.country_fr.*`,
UNNEST(first_contentful_paint.histogram.bin) AS bin
WHERE
origin = 'https://www.canyouseome.com')
WHERE
cdf / total >= 0.5
GROUP BY date
ORDER BY date
Comparer l’évolution du FCP médian de plusieurs sites
Vous savez comparer les densités de FCP rapide de plusieurs sites, vous savez calculer le FCP médian d’un seul site, vous savez obtenir l’évolution du FCP médian d’un seul site… du coup, il n’est pas très compliqué de comparer dans le temps le FCP médian de différents sites.
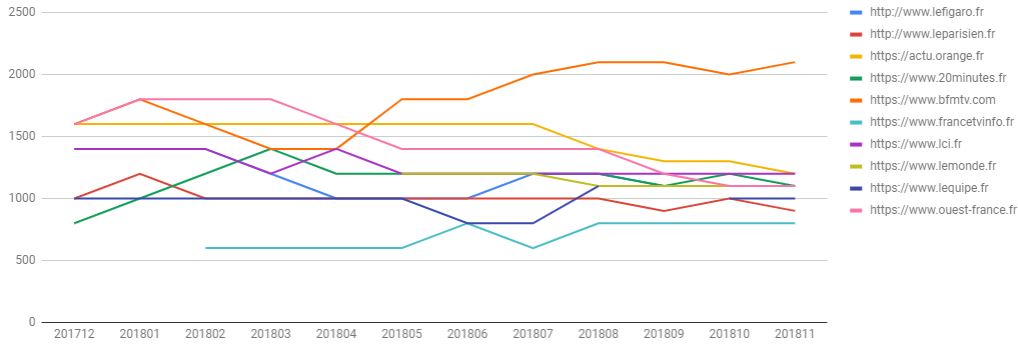
#standardSQL
SELECT
date,
origin,
MIN(start) AS median_fcp
FROM (
SELECT
_TABLE_SUFFIX as date,
origin,
bin.start,
SUM(bin.density) OVER (PARTITION BY _TABLE_SUFFIX, origin ORDER BY bin.start) AS cdf,
SUM(bin.density) OVER (PARTITION BY _TABLE_SUFFIX, origin) AS total
FROM
`chrome-ux-report.country_fr.*`,
UNNEST(first_contentful_paint.histogram.bin) AS bin
WHERE
origin IN (
'https://www.francetvinfo.fr',
'https://www.20minutes.fr',
'http://www.lefigaro.fr',
'https://www.lemonde.fr',
'https://actu.orange.fr',
'https://www.bfmtv.com',
'http://www.leparisien.fr',
'https://www.lci.fr',
'https://www.ouest-france.fr',
'https://www.lequipe.fr'
))
WHERE
cdf / total >= 0.5
GROUP BY date, origin
ORDER BY date, origin
Voilà, c’est tout pour aujourd’hui. Evidemment, on peut changer d’indicateur et ne pas se contenter du FCP. Rien qu’avec ces requêtes, on peut déjà obtenir un certain nombre d’information intéressante.
Dans un prochain article, nous verrons comment croiser les données du CrUX avec Wappalyzer, pour avoir plus d’information sur certaines technologies : cdn, cms, framework javascript, etc. etc. Si vous souhaitez que la suite apparaisse vite, dîtes-le moi dans les commentaires.
PS : bonne année et c’est gentil d’avoir tout lu.
PS 2 : je n’ai pas expliqué comment utiliser BigQuery, et vous n’aurez pas de tutoriel ici. Vous avez déjà les requêtes SQL, c’est déjà beaucoup.
PS3 : vous la sentez la blague venir ?
PS4 : au final, il est bien ou pas le nouveau Red Dead Redemption ?
Merci pour ton article et bonne année également.
Tu m’as perdu avec « Avec BigQuery, les données ne sont pas actualisées aussi rapidement que sur BigQuery » :p
j’ai rectifié 🙂
A quand les services pour monitorer ça automatiquement… D’ailleurs ça existe peut être sur les sites de monitoring (gtmetrix, pingdom, …), non ?
oui, il en existe mais généralement ils sont payants (et plus complets 🙂 ).
Speedcurve est plutôt bien par exemple.