Sommaire

Je suis actuellement Responsable SEO et web Analytics du groupe EBRA. J'ai ouvert ce blog pour partager des astuces, des tuto, ou des informations plus orientées techniques et opérationnelles.
- Looker Studio : gérer les dates et la granularité dans les graphs - 14 mars 2023
- Optimiser les pages avec les bons mots clés (DataStudio + Google Search Console) - 29 novembre 2020
- Seocamp 2020, les slides ? - 9 octobre 2020
Après avoir découvert l’API de Google Search Console via des add-ons, nous allons voir comment interroger directement l’API de Search Console. La présentation de l’API se trouve ici : https://developers.google.com/webmaster-tools. Deux méthodes sont présentées : l’API explorer, et les lignes de commande. Voici un tutoriel pour utiliser oacurl.
L’API explorer peut être pratique pour tester des requêtes, avoir un aperçu des résultats, etc. Les deux sont donc utiles et complémentaires.
Obtenir des identifiants pour l’API de Google Search Console
Pour utiliser l’API, il faut s’identifier…donc obtenir un accès. Pour cela, rendez-vous ici
https://console.developers.google.com/flows/enableapi?apiid=webmasters&credential=client_key&pli=1
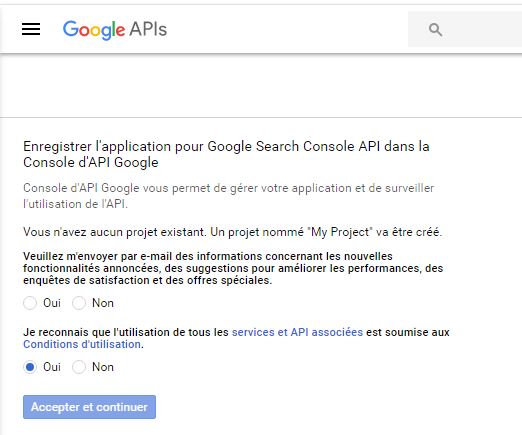
Vous acceptez ou non de recevoir des informations, acceptez les conditions d’utilisations, et continuer.
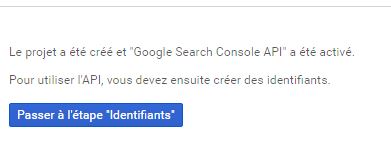
Une fois le projet créé, il faut récupérer des identifiants.
Quelle plateforme utilisez-vous pour appeler l’API ? nous allons utiliser oacurl, qui est une interface en ligne de commande, donc « Autre plateforme avec interface utilisateur« .
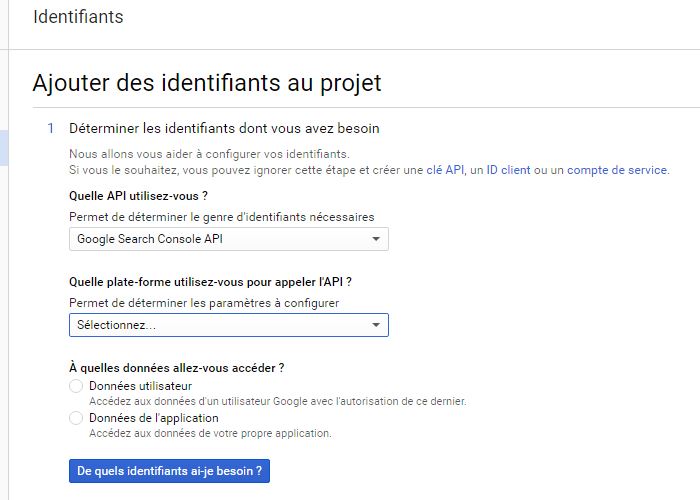
Nous allons accéder aux données utilisateurs.
Après avoir paramétré un nom d’utilisateur et valider quelques étapes, il est enfin possible d’avoir les identifiants.
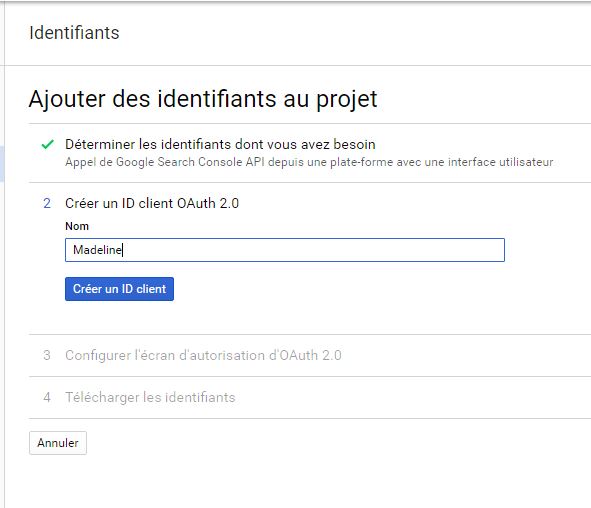
Vous devez donc avoir cet écran, avec votre nom d’utilisateur et votre ID client.
Télécharger oacurl
C’est par ici : https://code.google.com/archive/p/oacurl/downloads
Pourquoi oacurl ? c’est simple à utiliser…et cette BD de commitstrip résume très bien l’affaire :

Ensuite, il vous suffit d’ouvrir une fenêtre de commande et de vous identifier.
Accéder (enfin) à l’API de Google Search Console
Dans la fenêtre, vous devez copier cette commande, en remplaçant par vos propres identifiants :
java -cp oacurl-1.3.0.jar com.google.oacurl.Login --scope https://www.googleapis.com/auth/webmasters --oauth2 --consumer-key=VOTRE_CLIENT_ID --consumer-secret=VOTRE_CLIENT_SECRET
Normalement, une fenêtre doit s’ouvrir, pour vous connecter à votre compte google, et vous autorisez à accéder aux données de Google Search Console.

C’est bon, vous avez maintenant accès à l’API et faire plein de découvertes.
Lister tous les sites auxquels vous avez accès
Dans l’interface, ce sont les informations de la page d’accueil.
java -cp oacurl-1.3.0.jar com.google.oacurl.Fetch "https://www.googleapis.com/webmasters/v3/sites"
Vous obtiendrez tous les sites dont vous avez un accès, et quel niveau d’autorisation.
Connaître le nombre d’erreurs : dernier décompte ou dans le temps
Dans l’onglet Exploration > Erreurs d’exploration, vous avez un graph avec l’évolution du nombre d’erreurs par jour.
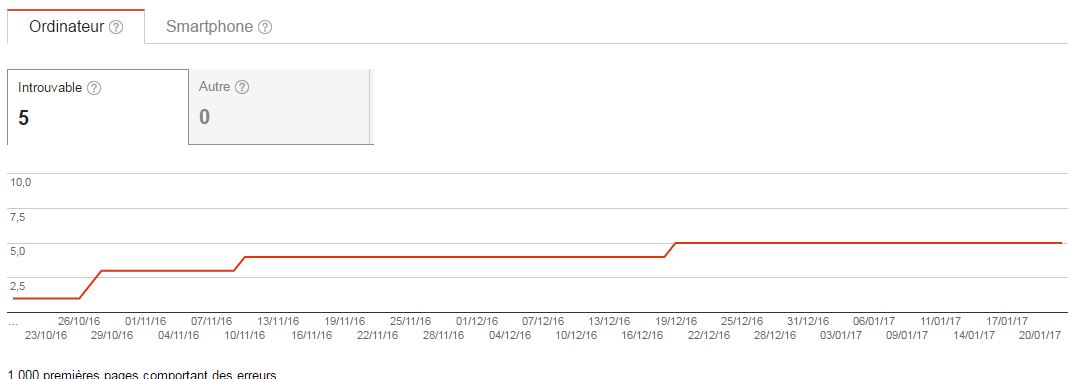
Avec l’API, il est possible de récupérer ces chiffres :
java -cp oacurl-1.3.0.jar com.google.oacurl.Fetch "https://www.googleapis.com/webmasters/v3/sites/VOTRE-SITE/urlCrawlErrorsCounts/query"
Lorsqu’on regarde la requête, il faut préciser un site, puis indiquer que l’on souhaite les infos sur les erreurs de crawl (urlCrawlErrorsCounts).
Avec cette requête, vous obtiendrez un résultat du type :
- plateform : web, smartphone
- category : types d’erreurs (
- notFound,
- notFollowed,
- authPermissions,
- serverError,
- soft404,
- roboted,
- manyToOneRedirect,
- flashContent,
- other)
- count : le nombre
- timestamp : l’heure de la dernière mise à jour
Du coup, en affinant la requête, vous pouvez filtrer.
Par exemple, pour les erreurs 404, il suffit d’ajouter category=notFound, et pour filtrer sur les erreurs trouvées par Googlebot normal ; plateform=web.
java -cp oacurl-1.3.0.jar com.google.oacurl.Fetch "https://www.googleapis.com/webmasters/v3/sites/VOTRE-SITE/urlCrawlErrorsCounts/query?category=notFound&platform=web"
Vous pouvez également avoir le nombre d’erreur par date, en ajoutant le paramètre latestCountsOnly=false
java -cp oacurl-1.3.0.jar com.google.oacurl.Fetch "https://www.googleapis.com/webmasters/v3/sites/VOTRE-SITE/urlCrawlErrorsCounts/query?latestCountsOnly=false"
Si vous avez beaucoup d’erreurs, vous aurez sûrement beaucoup de lignes qui vont se mettre à s’afficher sur votre fenêtre. Du coup, je vous conseille d’exporter les résultats en rajoutant « > liste-erreurs.txt »
Un fichier texte nommé « liste-erreurs.txt » devrait apparaître, avec toutes les données. C’est bien mais c’est moche, me direz-vous. Pour que ce soit joli, rien de tel que OpenRefine pour transformer vos fichiers json en CSV.
Lister les erreurs (et leurs sources)
Pour récupérer toutes les sources d’erreur, il faut maintenant multiplier les clics. Avec l’API, vous pouvez extraire très rapidement un fichier qui contient toutes ces informations.

On ne va plus faire appel à urlCrawlErrorsCounts mais urlCrawlErrorsSamples (on veut des listes, pas des chiffres).
Pour cette requête, plusieurs champs sont obligatoires :
- site
- category
- plateform
java -cp oacurl-1.3.0.jar com.google.oacurl.Fetch "https://www.googleapis.com/webmasters/v3/sites/VOTRE-SITE/urlCrawlErrorsSamples?category=notFound&platform=web"
Si vous comprenez la requête, normalement vous devriez comprendre que je demande la liste des erreurs 404 trouvées par Googlebot normal (pas les smartphones).
Pour chaque erreur trouvée (pageUrl), nous allons avoir la date de la découverte (first_detected), la date du dernier crawl (last_crawled), le code status (responseCode), les sources de l’erreur (urlDetails) :
- first_detected
- last_crawled
- pageUrl
- responseCode
- urlDetails
Pour les urlDetails, cela peut être divisé en 2 catégories : linkedFromUrls (erreur trouvée via des liens) ou containingSitemaps (via des sitemaps).
Vous aurez peut-être trop d’informations et certains champs vous sembleront inutiles. Rien ne vous empêche de modifier votre requête pour ne conserver que les champs nécessaires :
java -cp oacurl-1.3.0.jar com.google.oacurl.Fetch "https://www.googleapis.com/webmasters/v3/sites/VOTRE-SITE/urlCrawlErrorsSamples?category=notFound&platform=web&fields=urlCrawlErrorSample(last_crawled%2CpageUrl%2CresponseCode%2CurlDetails)"
Là, j’ai ajouté un paramètres « fields » pour dire que je ne voulais que la date du dernier crawl, la page, le code status et les sources.
Voilà, toute la doc de l’API est ici : https://developers.google.com/webmaster-tools/v3/parameters, vous pouvez explorer les autres possibilités.